Data:The dataset contained in this project has 4,303 records with 24 data series.
Recommender system:
Two most popular methods to develop a recommender system are collaborative filtering and content based recommendation systems. We will focus on collaborative filtering which system will recommend us movies that we haven’t watched yet, but users similar to us have, and like.
Cosine Similarity:
It is a method to measure the difference between two non zero vectors of an inner product space. See the example below to understand.
Data cleaning:The data set is pretty neat. I only removed the ones that had the lowest count of user ratings.
Modelling: I built this recommender calculating cosine similarity between movies. The similarity was calculated using two vectors that contained movie ratings.
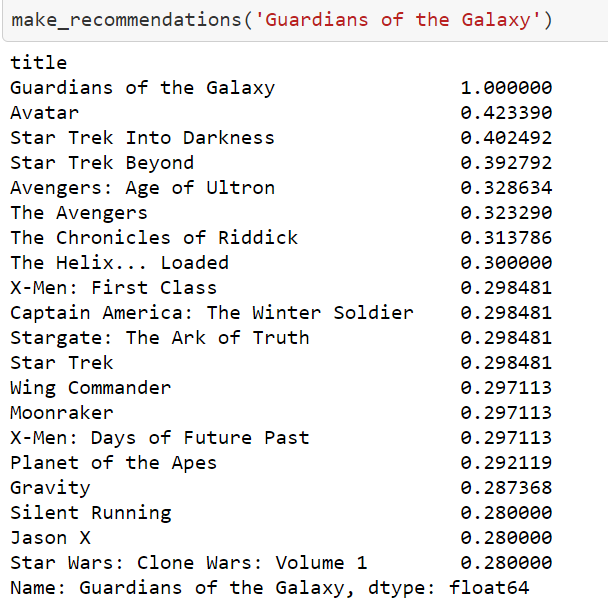
Testing system:
To test the system I provided it a movie ‘Guardian of Galaxy’ – and knew to certain extent what the recommendations would be. The first 3 movies in the recommendation list had a match with the genre.