The goal of this project is to predict and classify the fraud credit card transactions.
This dataset contains 284,807 transactions,out of which 492 belong to fraudulent transactions, which represents 0.17% of overall transactions. Therefore, this dataset is considered a highly imbalanced dataset and one of the main challenges we encounter in this project. There are 31 columns in the data, one being called “Feature” which is the target variable with containing the value of 1 being “Fraud” and zero means “Normal”
There are few issues we encounter which makes this project challenging to predict, most noticeably 28 of the columns are anonymous and does not reveal the identity due to confidential reasons, as well as this dataset is a highly imbalanced dataset to predict model.
We Will check Do fraudulent transactions occur more often during a certain time frame ? Let us find out with a visual representation.
![]()
Exploring the distribution by Class types through hours and minutes
![]()
Scaling Data
Since the features are a wide range of numerical values and not on the same scale. Therefore, we would need to convert them or shrink them to the same level between a mean of 0 and standard deviation of 1.
Used SMOTE (Synthetic minority oversampling) and ensemble learning/neural network on a highly imbalanced dataset of credit card transactions to classify them as fraudulent or legitimate.
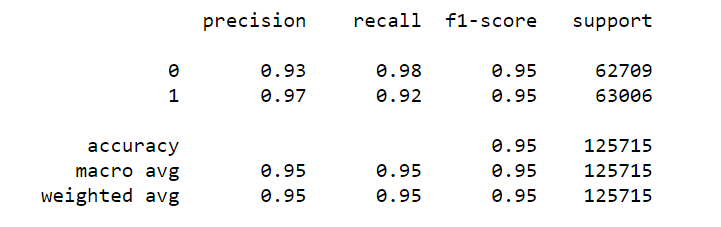
Logistic Regression
As we have to predict the binary classes which means only two possible classes can be identified. Therefore, it is wise to leverage the Logistic regression model which computes the probability of an event occurrence, which in this case is Normal vs Fraud transaction.
Confusion Matrix:
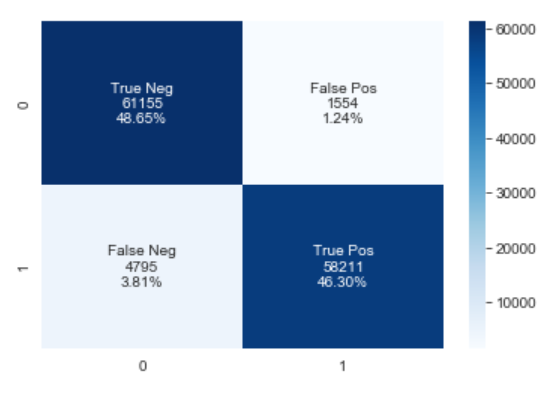
Conclusion:
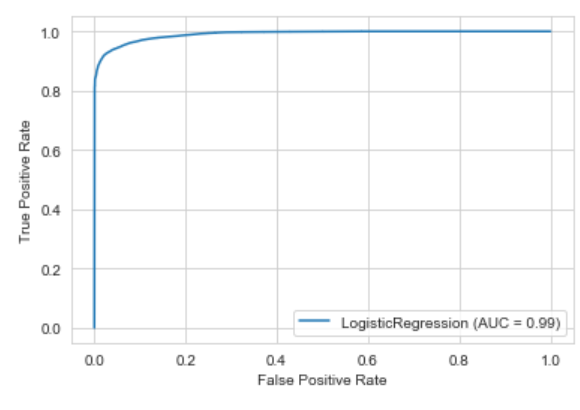
Performed data exploratory techniques using Python, which built the model that predicted the likelihood of the transaction being fraudulent. The Logistic regression model achieved 95% f1-score and AUC of 99% and yield an accuracy of 95%